Recovering Weber's law a unit test for the WPPM¶
Goal: show that a flexible 1-D WPPM, told nothing about the functional form of perception, relearns Weber's law from raw binary "which one is the odd one out?" answers.
The complete runnable script is
weber_law_demo.py. For the 2-D covariance-ellipse workflow, start with the quick start or the end-to-end full WPPM fit tutorial.
This tutorial assumes you are comfortable with psychophysics (Just noticable difference (JND), psychometric
functions, signal-detection ideas) but new to psyphy. We restate just enough of the
classical laws to fix notation, then demonstrate, how the Wishart Psychophysical Process Model can recover the predictions Weber's Law makes -- one of the core laws in psychophysics.
The idea in one paragraph¶
Weber's law says the just-noticeable difference (JND) is a constant fraction of the stimulus level:
Heavier baselines need proportionally larger changes; the fraction \(k\) stays fixed. Fechner's law is the corollary you get by walking the stimulus axis one JND at a time perceived magnitude grows logarithmically:
The WPPM (Wishart Process Psychophysical Model) does not assume any of this. It learns a field of discrimination noise \(\Sigma(s)\) over stimulus space and lets the law fall out of the data. So we can run a clean experiment:
Recovering Weber's Law predictions as a unit test for models of perception
Generate binary oddity responses from a synthetic observer that obeys Weber's law exactly. Hand the WPPM only those responses (never \(k\) and the never the linear form). If it recovers a noise function whose implied threshold scales linearly with \(s\), the model is flexible enough to represent Weber's law. WPPM-recovers-Weber becomes a 'unit test ' for the package.
Weber's law in WPPM language¶
The WPPM parametrizes a square root of the covariance, \(\Sigma(s) = U(s)\,U(s)^\top\), which guarantees \(\Sigma\) stays positive. In 1-D this is just \(\sqrt{\Sigma(s)} = U(s)\), and \(\sqrt{\Sigma(s)}\) is our JND proxy (threshold \(\propto\) noise SD).
So Weber's law translates to a single line:
\(U(s)\) is represented in a Chebyshev basis over a normalized coordinate \(x\in[-1,1]\), \(U(x)=\sum_i W_i\,T_i(x)\). Because Weber needs \(U\) linear, a degree-1 basis (\(U(x)=W_0+W_1 x\), two parameters) is exactly sufficient but we deliberately fit a more flexible model (degree 3 polynomial) and check it doesn't overfit.
Runtime¶
| Hardware | Approximate time |
|---|---|
| CPU (laptop / M-series Mac) | 1–3 min |
The fit uses N_TRIALS = 2000 trials and MC_SAMPLES = 1000 Monte-Carlo draws per trial;
the optional basis sweep at the end refits the model several times and is the slow part (3 min).
Step 1 Stimulus domain and coordinates¶
The Chebyshev basis we use requires stimuli to be in \([-1, 1]\). We pick a physical range
[S_MIN, S_MAX] wide enough to hold the largest comparison and map physical \(s\) to
normalized \(x\) explicitly:
References are drawn from [S_MIN, S_MAX_REF] = [0.2, 1.0]; comparisons can reach up to
S_MAX_REF·(1 + 4·k) = 1.8, comfortably inside S_MAX = 2.0.
Step 2 The ground-truth Weber observer¶
This is the synthetic participant that generates our data. It implements only the one
method OddityTask needs a square-root covariance U and hard-codes Weber's law,
\(\sqrt{\Sigma(s)} = k\,s\). It receives the same normalized \(x\) as the WPPM and converts
back to physical \(s\) internally, so simulation and fitting share one coordinate system.
Step 3 Simulate oddity-task data¶
The experiment settings:
Each trial is a 3-AFC oddity: two identical references and one comparison; the observer picks the odd one out. We place each comparison a random number of JNDs (0.5–4) above its reference, so the data spans easy and hard trials, then draw a binary correct/incorrect response from the Monte-Carlo oddity likelihood.
The stored TrialData holds only (stimuli, responses) exactly what an experimenter
records. Plotting reference level \(s\) against displacement \(\delta = s_\mathrm{comp} -
s_\mathrm{ref}\), with the ground-truth JND line \(\delta = k\,s\), shows the structure the
model must recover: trials above the line are mostly correct, below mostly wrong.
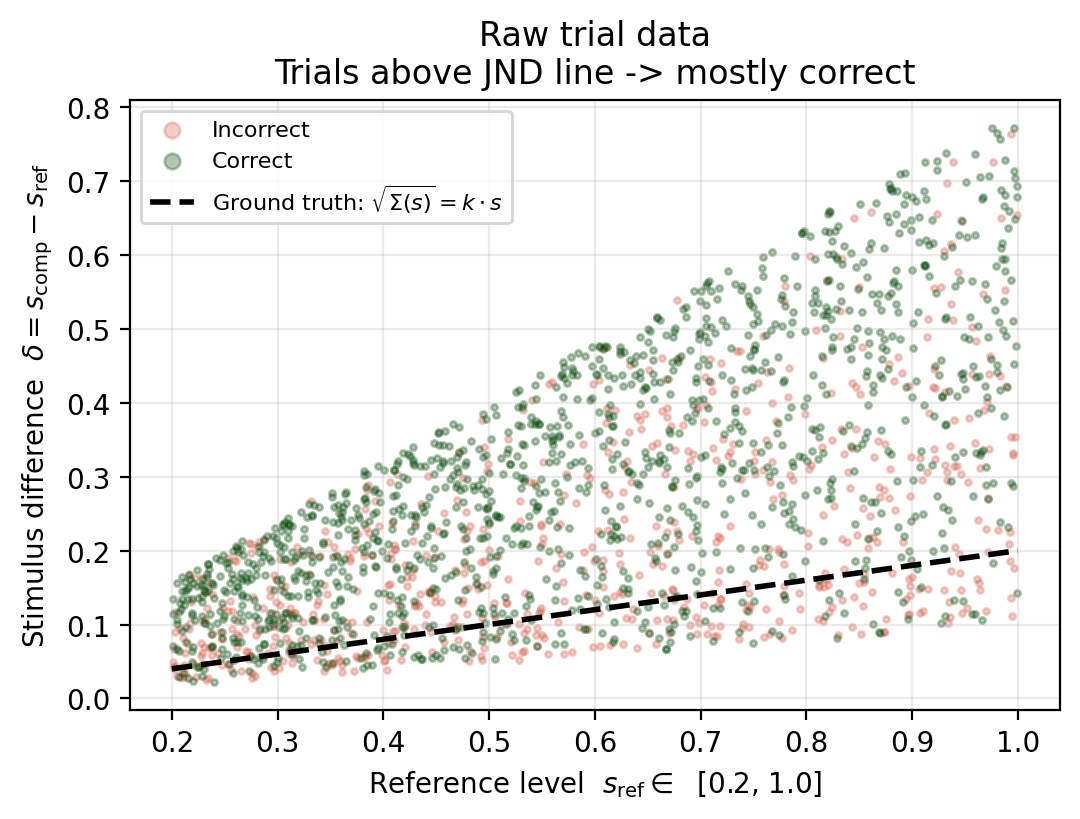
The model sees only these binary outcomes never the dashed ground-truth line.
Step 4 Fit a 1-D WPPM¶
We build a WPPM with a degree-3 Chebyshev basis more flexibility than Weber needs
and fit it by MAP. Crucially, the model sees only the responses: never \(k\), never the
linear form. (BASIS_DEGREE_FIT = 3 is set just above this block in the script.)
MAPOptimizer runs SGD + momentum and returns a posterior whose .params are the fitted
Chebyshev weights \(W\).
Step 5 Read the recovered function three ways¶
Bind the fitted parameters into a WPPMCovarianceField and evaluate \(\Sigma(s)\) on a dense
grid. From the single fitted function \(\sqrt{\hat\Sigma(s)}\) we read three views the first
three panels are the same fit re-expressed.
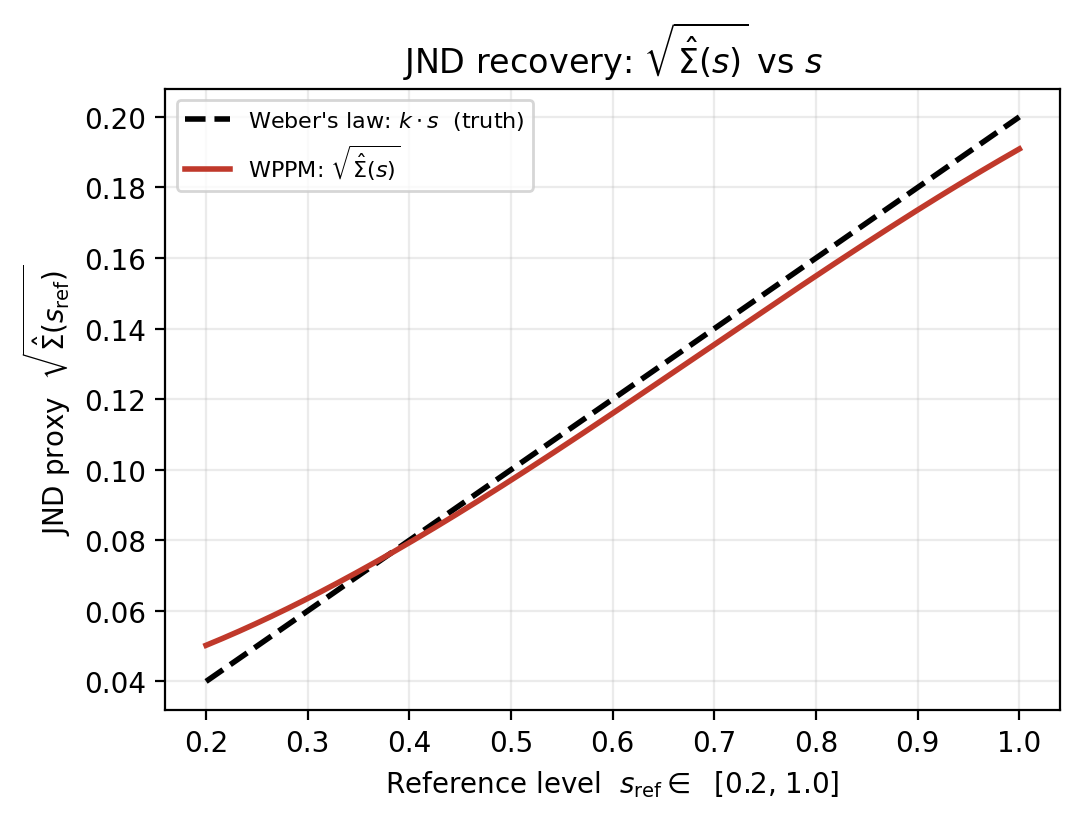
(a) JND recovery. \(\sqrt{\hat\Sigma(s)}\) vs \(s\) should be a straight line through the origin with slope \(k\).
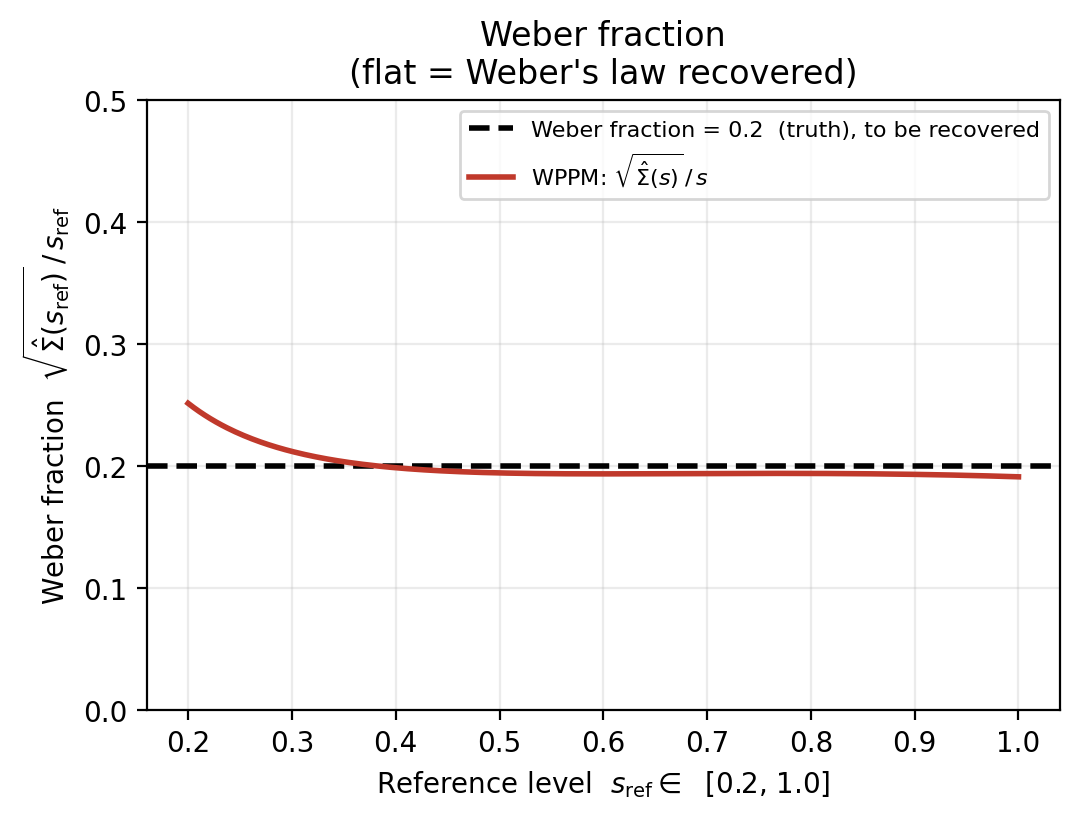
(b) Weber fraction Divide by \(s\): \(\sqrt{\hat\Sigma(s)}/s\) should be flat at \(k = 0.2\). A flat line is the defining signature of Weber's law in this figure.
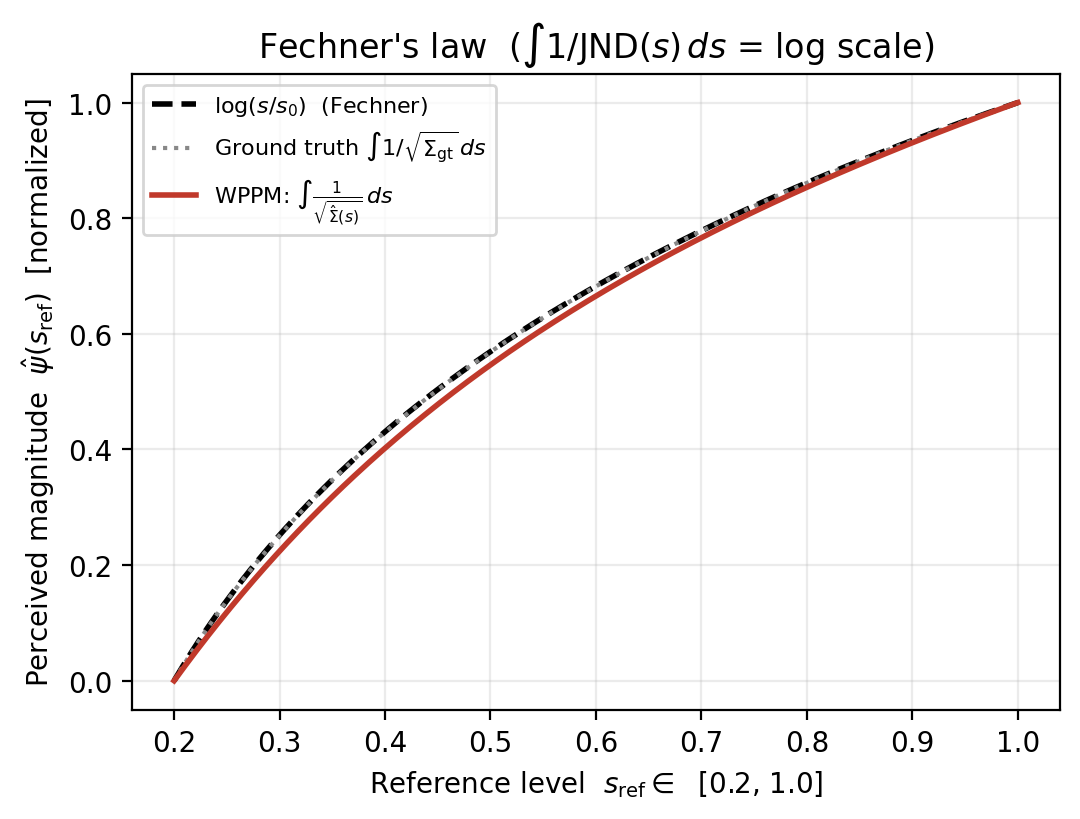
(c) Fechner's law for free. Integrate \(1/\sqrt{\hat\Sigma(s)}\); the result is the logarithmic sensation scale a deterministic transform of the same curve the model was never fit to.
Step 6 Behavioral check: psychometric curves¶
The three views above are algebra are '3 sides of the same coin'.
Psychometric curve:¶
If Weber's law has been recovered, the sigmoids shift right in proportion to \(s\): a larger baseline needs a proportionally larger \(\delta\) for the same performance. Chance for a 3-AFC oddity task is \(1/3\).
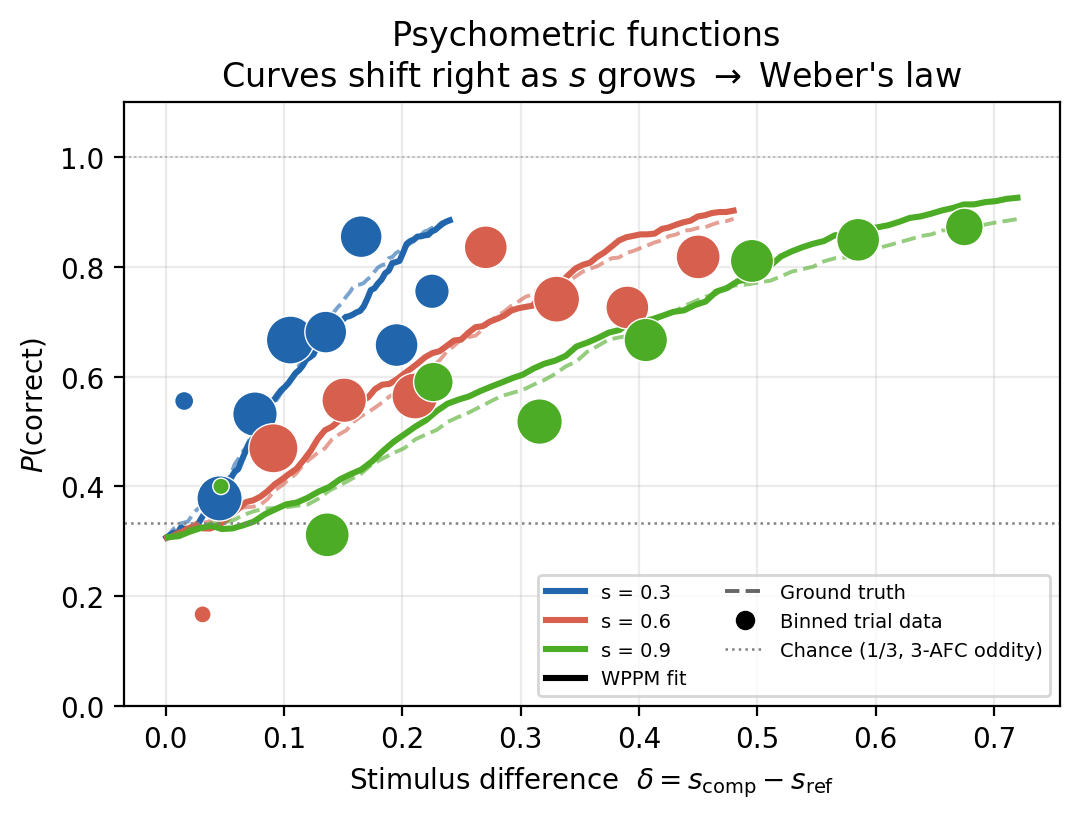
Solid: WPPM fit. Dashed: ground truth.
Step 7 Learning curve (what we optimized)¶
The optimizer's history is the negative log-posterior per step; this is exactly the
quantity MAPOptimizer minimizes:
The only free parameters are the Chebyshev weights \(W\) that define \(U(x)\) and hence \(\Sigma(x)\). The two terms are:
- Log-likelihood: summed over all trials, \(\sum_i \big[r_i \log p_i + (1-r_i)\log(1-p_i)\big]\), where \(p_i = P(\text{correct})\) for trial \(i\) from the Monte-Carlo oddity decision process under the current \(\Sigma\). It rewards predicted correctness probabilities that match the observed 0/1 responses.
- Log-prior: a Gaussian shrinkage \(-\tfrac12\sum_n W_n^2/\sigma_n^2\) that pulls weights (especially higher-order ones) toward zero. This is the regularization that makes the model prefer plain Weber over a wiggly fit.
| Access the learning curve | |
|---|---|
If you're new to reading a learning curve:
The likelihood is Monte-Carlo estimated, with a fresh random key drawn every step, so each point is a noisy estimate of the loss. We only care about the trend and not individual points which may jitter due to MC noise,
which is not a problem.
1 2 3 4 5 6 7 | |
The script assembles every result (the four diagnostic panels, the psychometric curves, and this learning curve) into one figure:
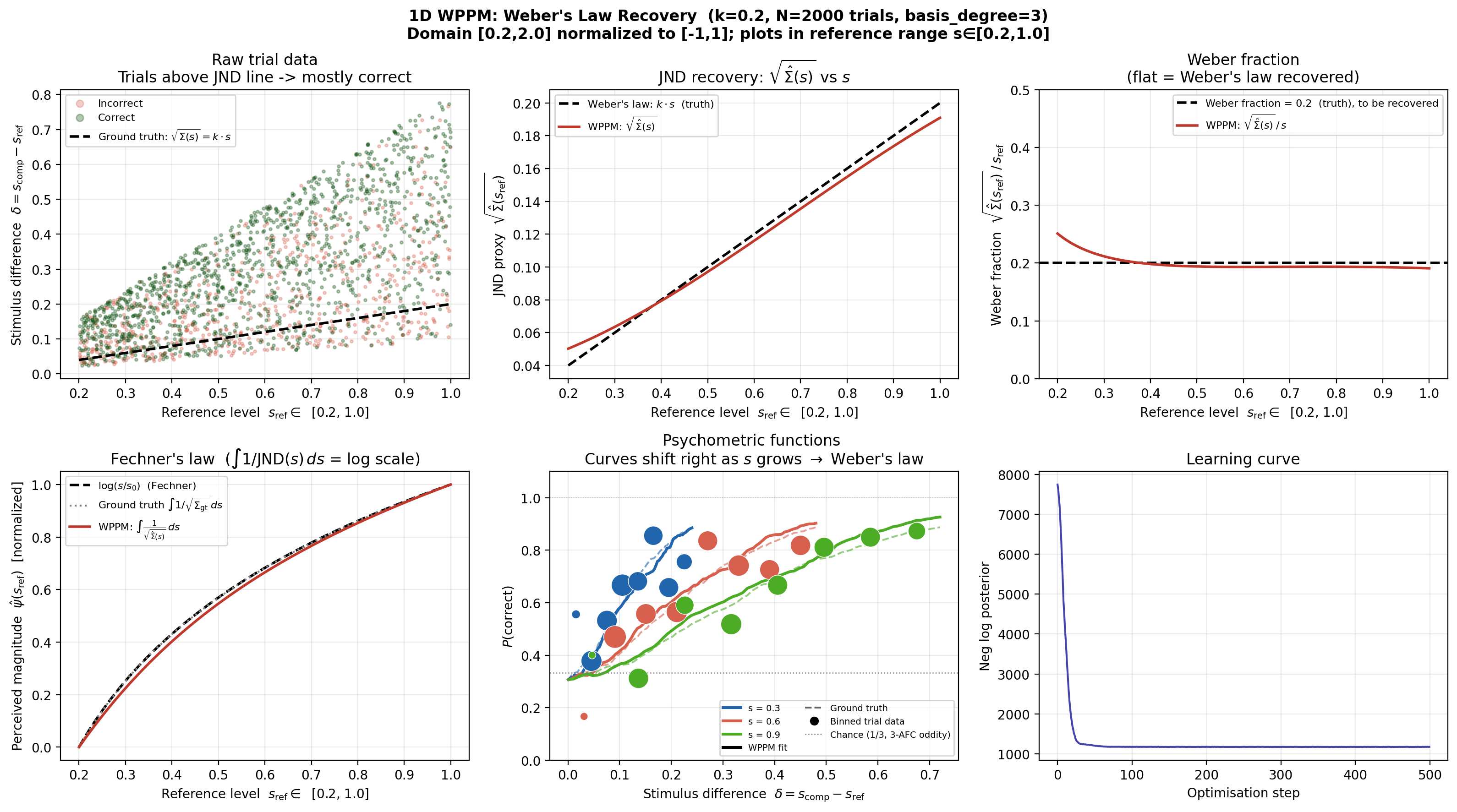
All results at a glance; the learning curve is the bottom-right panel.
Step 8 How much flexibility did the data actually need?¶
We fit a degree-3 model, but Weber only needs degree 1. Training fit alone can't tell us which is right (more parameters never fit worse), so we split the trials, fit on the training set across several basis degrees, and score the held-out log-likelihood:
Degree 0 (a constant \(U\), hence a constant JND) cannot bend and underfits; degree 1 (linear \(U\) -> quadratic \(\Sigma\)) peaks; degree 2+ adds no held-out gain. The data needs exactly the flexibility Weber's law implies, ie, linear.
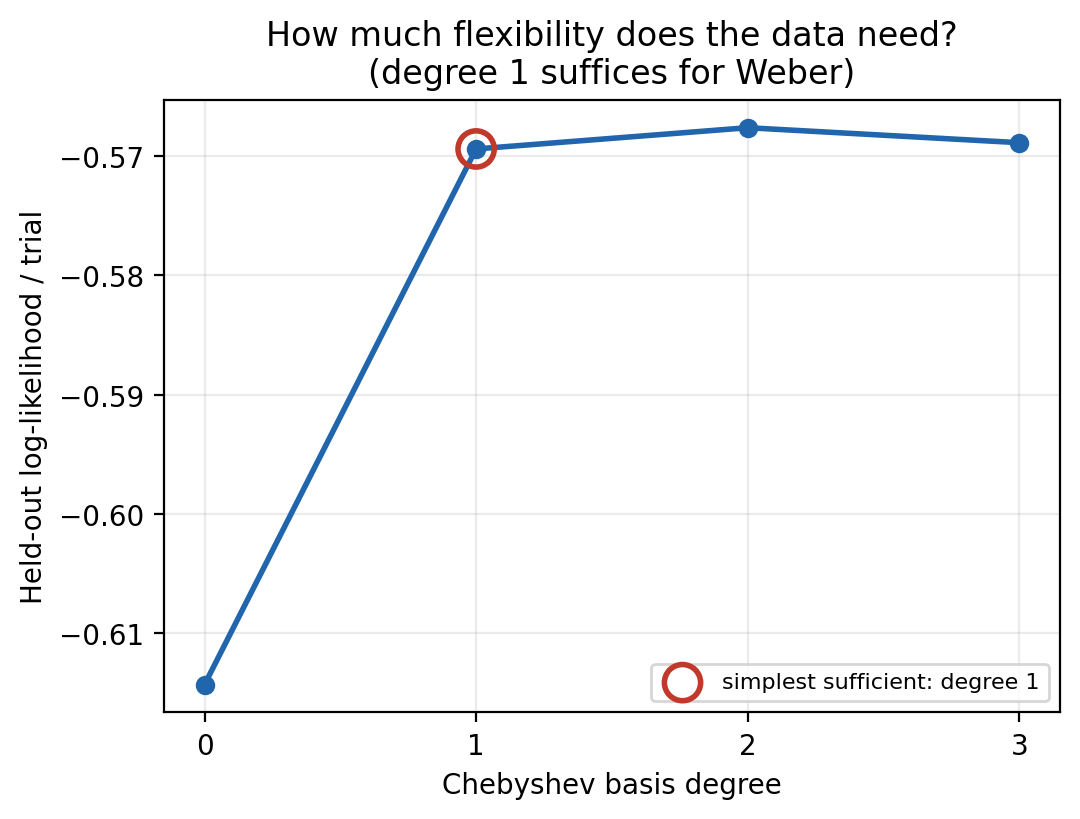
Verdict
Given only binary "which is different?" answers, the WPPM with no linear law encoded recovers everything Weber's law predicts: a constant fraction, a logarithmic sensation scale, and psychometric curves that shift with stimulus level. The unit test passes :)
Next steps¶
- Your own data: replace the simulated
TrialDatawith realstimuliandresponses, and validate via held-out psychometric curves where no ground truth exists. - Beyond Weber: the same machinery represents other regimes (e.g. de Vries–Rose \(\delta_\mathrm{th}\propto\sqrt{s}\)) -> fit them the same way and read off the recovered law.
- Fewer trials: put trials where uncertainty is highest with adaptive trial placement.
- API reference:
MAPOptimizer,WPPM, andWPPMCovarianceField. - 2-D workflow: the quick start and the full WPPM example fit spatially-varying covariance ellipses.