Hosting a Dendro compute resource
Each Dendro project comes equipped with a dedicated compute resource for executing analysis jobs. The default setting uses a compute resource provided by the authors with limitations on CPU, memory, and concurrent jobs, shared among all users. This public resource should only be used for testing with small jobs. Contact one of the authors if you would like to run more intensive processing or configure your own compute resources.
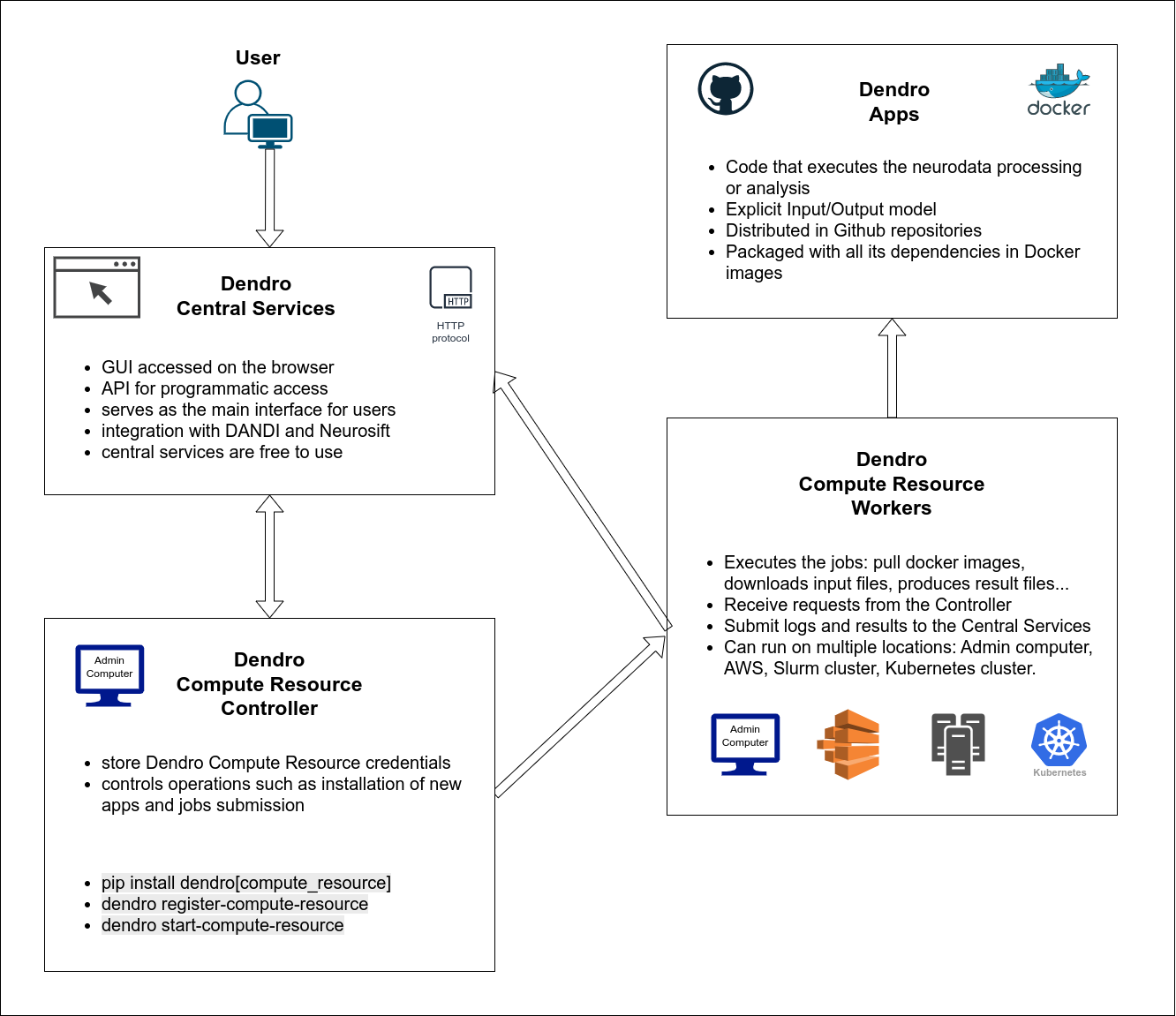 Figure 1 - Diagram of Dendro architecture.
Figure 1 - Diagram of Dendro architecture.
In order to submit Dendro jobs, you will need to host a compute resource. This can be done on your local machine, or on a cloud service like AWS. The compute resource is composed of two parts: a controller node and worker nodes.
The controller node is where the Dendro Daemon process runs. This is a lightweight process that will comunicate with the central services, subscribe to a PubSub service to accept new job requests and submit these jobs to the worker nodes. The controller node should hold the credentials necessary to submit jobs to the worker nodes.
Worker nodes are instances where the jobs will actually run. These can be configured to run on multiple locations:
- on a local machine (same as the Controller node)
- on a cloud service like AWS
- on a Slurm cluster
- on a Kubernetes cluster
Start a compute resource controller
- Python >= 3.9
- Docker or apptainer (or singularity >= 3.11)
The compute resource controller process should be running when you submit jobs to Dendro.
1. Install the Dendro package:
pip install dendro[compute_resource]
2. Register a new compute resource. On an empty directory, run the following commands:
export CONTAINER_METHOD=apptainer # or docker
dendro register-compute-resource
On the terminal you will see a generated link. Open the link in a browser and log in using GitHub. Finalize the registration process in the web interface. This will create a hidden file called .dendro_compute_resource.json in the current directory.
.dendro_compute_resource.json
The controller node configuration file is generated by the dendro register-compute-resource command. It contains the following information (example):
AVAILABLE_JOB_RUN_METHODS: local
COMPUTE_RESOURCE_ID: xxxxxxxxxxxxxxxxxxxxxxxxxx
COMPUTE_RESOURCE_PRIVATE_KEY: xxxxxxxxxxxxxxxxxxxxx
CONTAINER_METHOD: docker
DEFAULT_JOB_RUN_METHOD: local
3. Start the compute resource controller process:
dendro start-compute-resource
Leave this process open in a terminal, it is recommended that you use a terminal multiplexer like tmux or screen. While this process is running, you will be able to install new apps and submit jobs to Dendro. If this process is terminated, you can restart it with the same command, in the same directory containing the .dendro_compute_resource.json file.
Compute resource worker nodes
The worker nodes are where the heavy data processing jobs will actually run, and usually require more resources in terms of CPU, memory, GPU and storage. Dendro supports workers nodes running on multiple technologies.
- Local worker nodes: when running the compute resource controller on any machine, this machine can also be used as a local worker node. This is ideal for testing and lightweight jobs, but does not scale well for large jobs or multiple concurrent jobs.
- Worker nodes: AWS Batch
- Worker nodes: Slurm
- Worker nodes: Kubernetes
Configuring apps for your compute resource
In order to run jobs with your compute resource, you will need to configure apps to use it.
In the web interface, click on the appropriate link to manage your compute resource. You will then be able to add apps to your compute resource by entering the information (see below for available apps).
⚠️ After you make changes to your compute resource on the web interface, reload the page so that your changes will take effect.
The following are available apps that you can configure