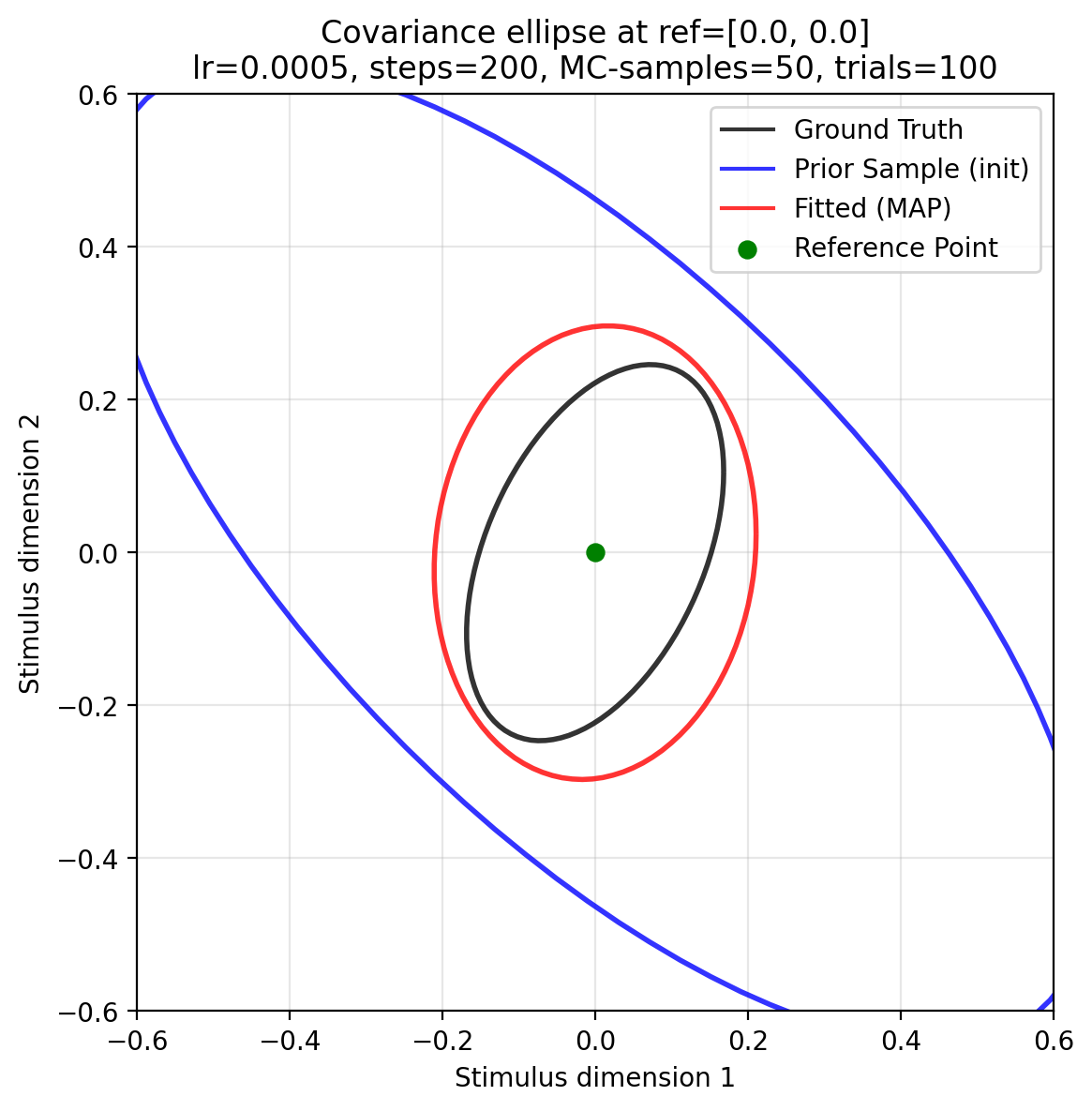
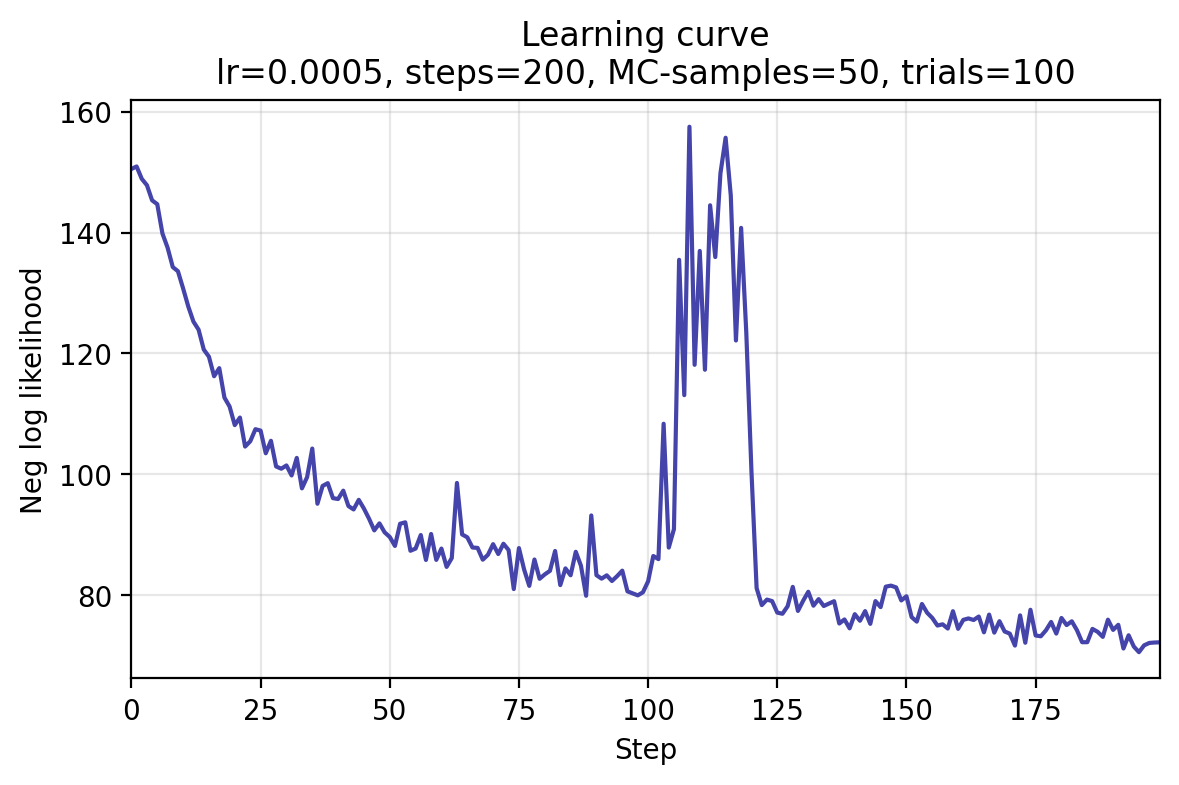
Quick-start walkthrough — fit your first covariance ellipse¶
The snippet below shows the minimal end-to-end workflow: simulate a handful of
oddity-task trials at a single reference point, fit the WPPM with MAP
optimization, and visualize the result. No GPU needed — runs in under 2 min
on CPU.
MC_SAMPLES=50# MC samples per trial in the likelihood (full example: 500)NUM_TRIALS=100# total simulated trials (full example: 4000 × 25)NUM_STEPS=200# optimizer steps (full example: 2000)learning_rate=5e-4# full example: 5e-5. The smaller the lr, the more steps# are required.
task=OddityTask(config=OddityTaskConfig(num_samples=int(MC_SAMPLES)))noise=GaussianNoise(sigma=0.1)# Set all Wishart process hyperparameters in Priortruth_prior=Prior()truth_model=WPPM(prior=truth_prior,likelihood=task,noise=noise,)# Sample ground-truth Wishart process weightstruth_params=truth_model.init_params(jax.random.PRNGKey(123))
inference=MAPOptimizer(steps=NUM_STEPS,learning_rate=learning_rate,track_history=True,log_every=1,)map_estimate=inference.fit(model,data,init_params=init_params,seed=4)# Protocol: ParameterPosterior, here point estimate# optional: for visualization:map_cov_field=WPPMCovarianceField(model,map_estimate.params)# OUTPUT: Covariance Matrices (N, 2, 2) for plotting